Breaking it down: Questions about AI
For many of us, AI seems pretty futuristic. Recently, though, it’s been showing up, more and more, in our lives — whether it’s a Google computer playing an amazing game of Go, or Inbox by Gmail creating auto replies. And while that’s all exciting, some of us are still wondering about the basics of AI. Or why it matters. Or why identifying a dog in a photo isn’t as easy as it sounds. So we sat down with Maya Gupta, research scientist for AI at Google, for an introduction to AI.
Let’s start with the basics of AI. What exactly is it?
AI takes a bunch of examples, figures out patterns that explain the examples, then uses those patterns to make predictions about new examples.
Take movie recommendations, for example. Say a billion people each tell us their ten favorite movies. That’s a bunch of examples the computer can use to learn what movies that people like have in common. Then the computer comes up with patterns to explain those examples like maybe, “People who like horror movies don’t usually like romances, but people do like movies with the same actors in them.” Then if you tell the computer you liked The Shining with Jack Nicholson, it can make a good guess about whether you’d like the romantic comedy Something’s Gotta Give with Jack Nicholson, and which other videos to recommend to you on YouTube.
Got it. Sort of. How does that work in practice, though?
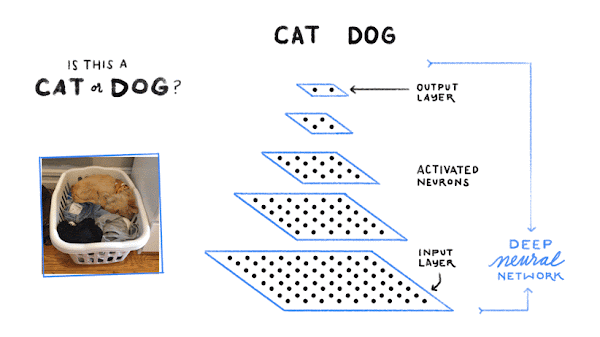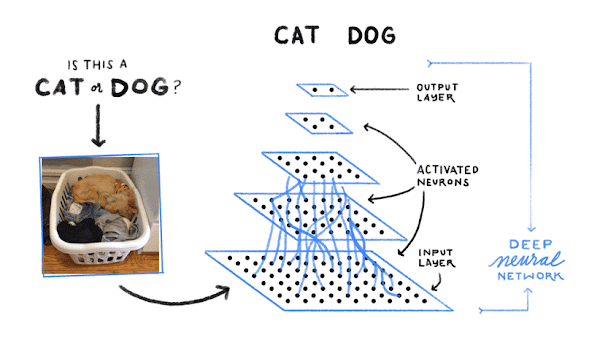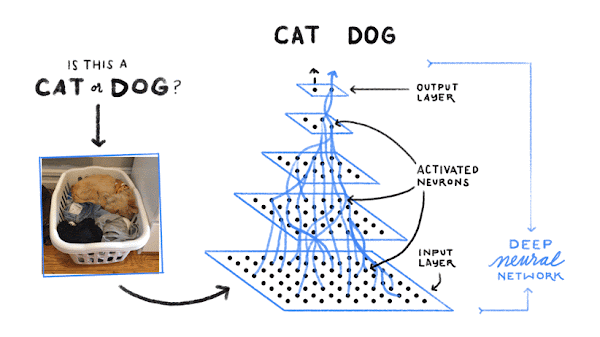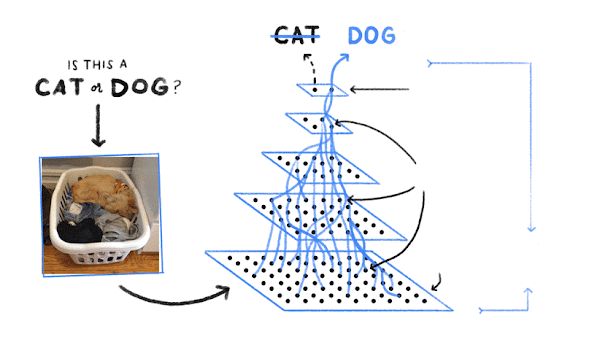
In practice, the patterns that the machine learns can be very complicated and hard to explain in words. Consider Google Photos, which lets you search your photos to find pictures with dogs. How does Google do that? Well, first we get a bunch of examples of photos labeled “dog” (thanks internet!). We also get a bunch of photos labeled “cat,” and photos with about a million other labels, but I won’t list them all here :).

Then the computer looks for patterns of pixels and patterns of colors that help it guess if it’s a cat or dog (or…). First, it just makes a random guess at what good patterns might be to identify dogs. Then it looks at an example dog image, and sees if its current patterns get it right. If it’s mistakenly calling a cat a dog, then it makes some tiny adjustments to the patterns it’s using. Then it looks at a cat image, and again tweaks its patterns to try to get that one right. And it repeats this about a billion times: look at an example, and if it’s not getting it right, tweak the patterns it’s using to do a better job on that one example.
In the end, the patterns form an AI model, such as a deep neural network, that can (mostly) correctly identify dogs and cats and fire fighters and many, many other things.
That sounds pretty futuristic. What are some of the other Google products that use AI today?
There’s a whole host of new things Google is doing with AI, like Google Translate can take a photo of a street sign or menu in one language, figure out the words and language that are in the photo, and magically translate it real-time into your language.
You can also say just about anything to Translate and AI speech recognition will kick in. Speech recognition is used in a bunch of other products as well, like figuring out your voice queries for the Google app, and making YouTube videos more searchable.



For signs, menus, etc, just point your camera and get an instant translation. You don’t even need an internet connection. *Word Lens available between English and over two dozen languages.
Talk with someone who speaks a different language.
Easily handwrite characters and words not supported by your keyboard.
Simply type the words you want to translate.
So, why is Google making such a big deal about AI now?
AI is not brand new, and has its roots in 18th century statistics. But you’re right it has really heated up lately for three reasons.
First off, we need a huge number of examples to teach computers how to make good predictions, even about stuff you or I would find easy (like finding a dog in a photo). With all the activity on the internet, we’ve now got a rich source of examples computers can learn from. For example, there are now millions of dog photos labeled as “dog” on websites around the world, in every language.
But it’s not enough to have a lot of examples. You can’t just show a bunch of photos of dogs to a webcam and expect it to learn anything — the computer needs a learning program. And lately the field (and Google) has made some exciting breakthroughs in how complicated and powerful those AI programs can be.
However, our programs are still not perfect, and computers are still pretty dumb, so we have to see a lot of examples a bunch of times to tweak a lot of digital knobs to get it right. That all takes a huge amount of computing power, and fancy parallelized processing. But new software and hardware advancements have made that possible, too.
What’s one thing computers can’t do today, but will be able to do soon, thanks to AI?
Practically yesterday, speech recognition struggled to recognize just ten different digits when you read your credit card number over the phone. Speech recognition has made incredible advances in the last five years using sophisticated AI, and now you can use it to issue Google searches. And it’s getting even better, fast.
I think AI is even going to make us all look better. I don’t know about you, but I hate trying on clothes! I find a brand of jeans that works, and I buy five of them. But AI can turn examples of which brands fit us into recommendations for what else should fit us. That problem’s a little outside of Google’s scope, but I hope someone’s working on it!
What does AI look like in ten years?
One thing the whole field is working on is how to learn faster from fewer examples. One approach to that (that Google is working particularly hard on) is giving our machines more common sense, which in the field we call “regularization.”
What does common sense look like to a machine? Well one thing it means is that, in general, if an example only changes a little, the machine shouldn’t totally change its mind. For example, a photo of a dog with a cowboy hat is still a dog.
We enforce this kind of common sense in the learning program by making the AI insensitive to small, unimportant changes, like a cowboy hat. While that’s easy to say, if you do it wrong, you make the machine not sensitive enough to important changes! So this a balancing act we’re still figuring out.

What excites you most about AI? What motivates you to work on it?
I grew up in Seattle, where we learned a lot about early explorers of the American West like Lewis and Clark. AI research has that same spirit of exploration — we’re seeing things for the first time, and trying to map out a path to a great future.
If you could give AI at Google a bumper sticker slogan, what would it be?
If at first you don’t succeed, try another billion times.




